[Home]->[Project]->[Visualizing Image Categorization]
[English]
アンカーマップを用いた
Bag-of-features 画像カテゴリ分類の可視化
Yi Gao,
Hsiang-Yun Wu,
Kazuo Misue,
Kazuyo Mizuno,
and
Shigeo Takahashi
The 7th International Symposium on Visualization & Interaction
(VINCI 2014)
このウェブページは,画像カテゴリ分類の可視化に関する研究結果を提供するために準備されました.
|
|
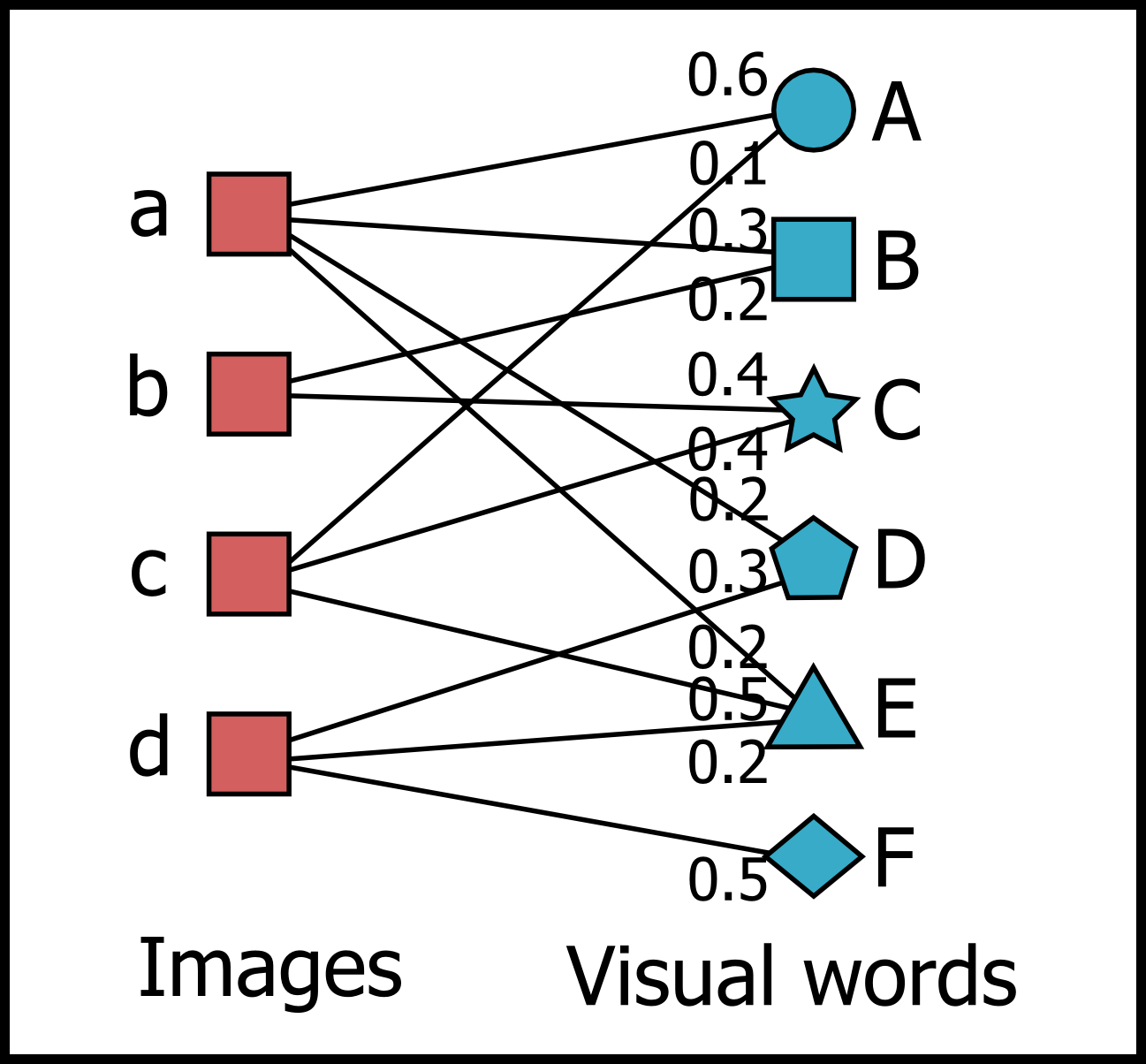
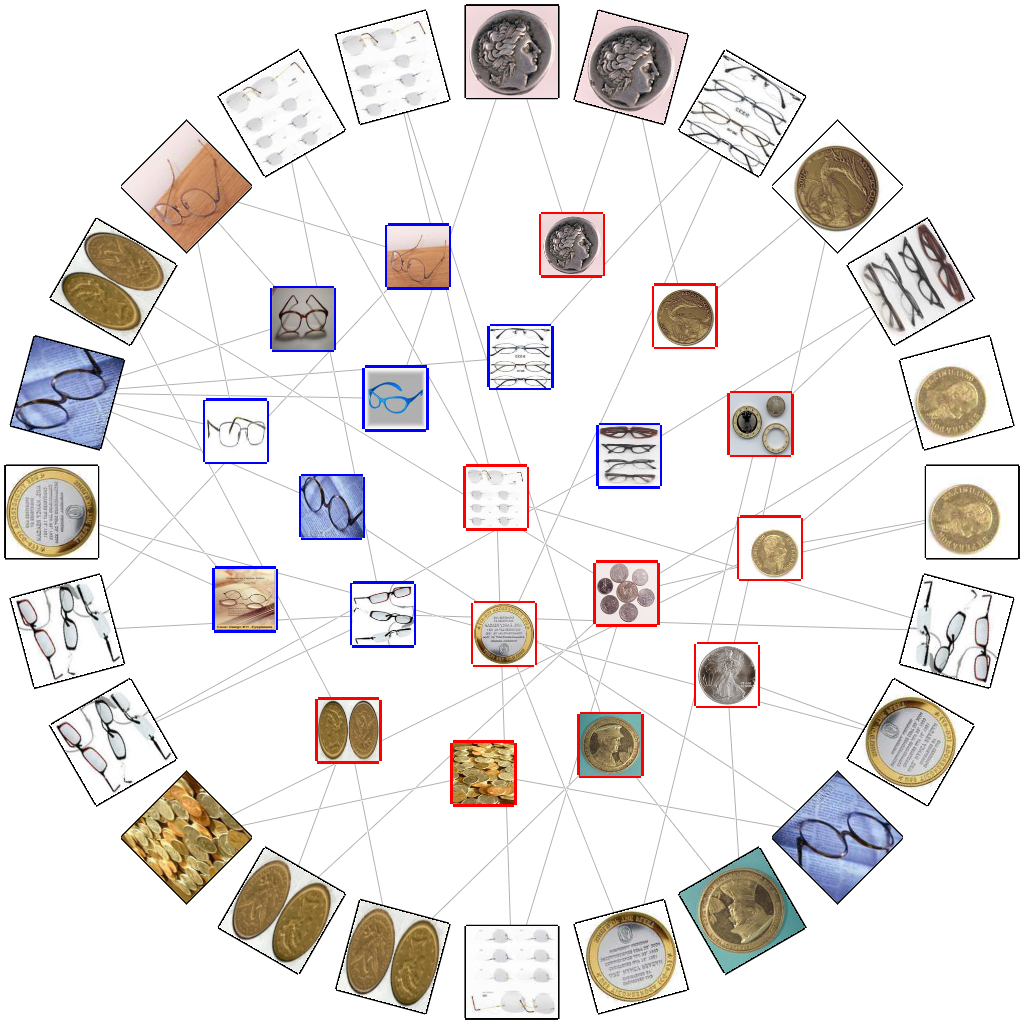
各画像は,図2にあるように BoF モデルにおける visual word の粗ベクトルとして表現される.
本手法では,
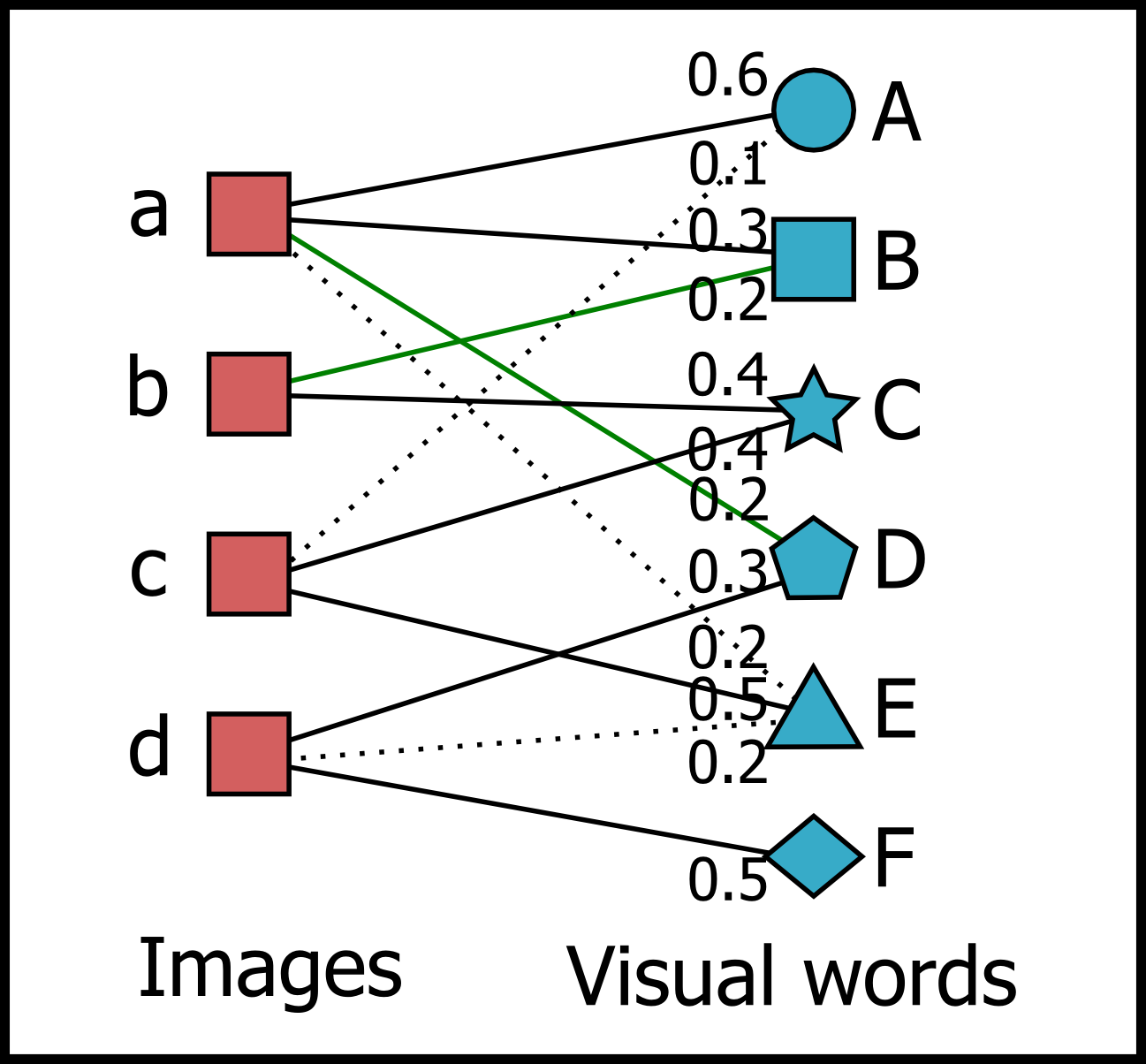
各画像を限定された個数の visual word と関連付けることで2部グラフを構成しのち,
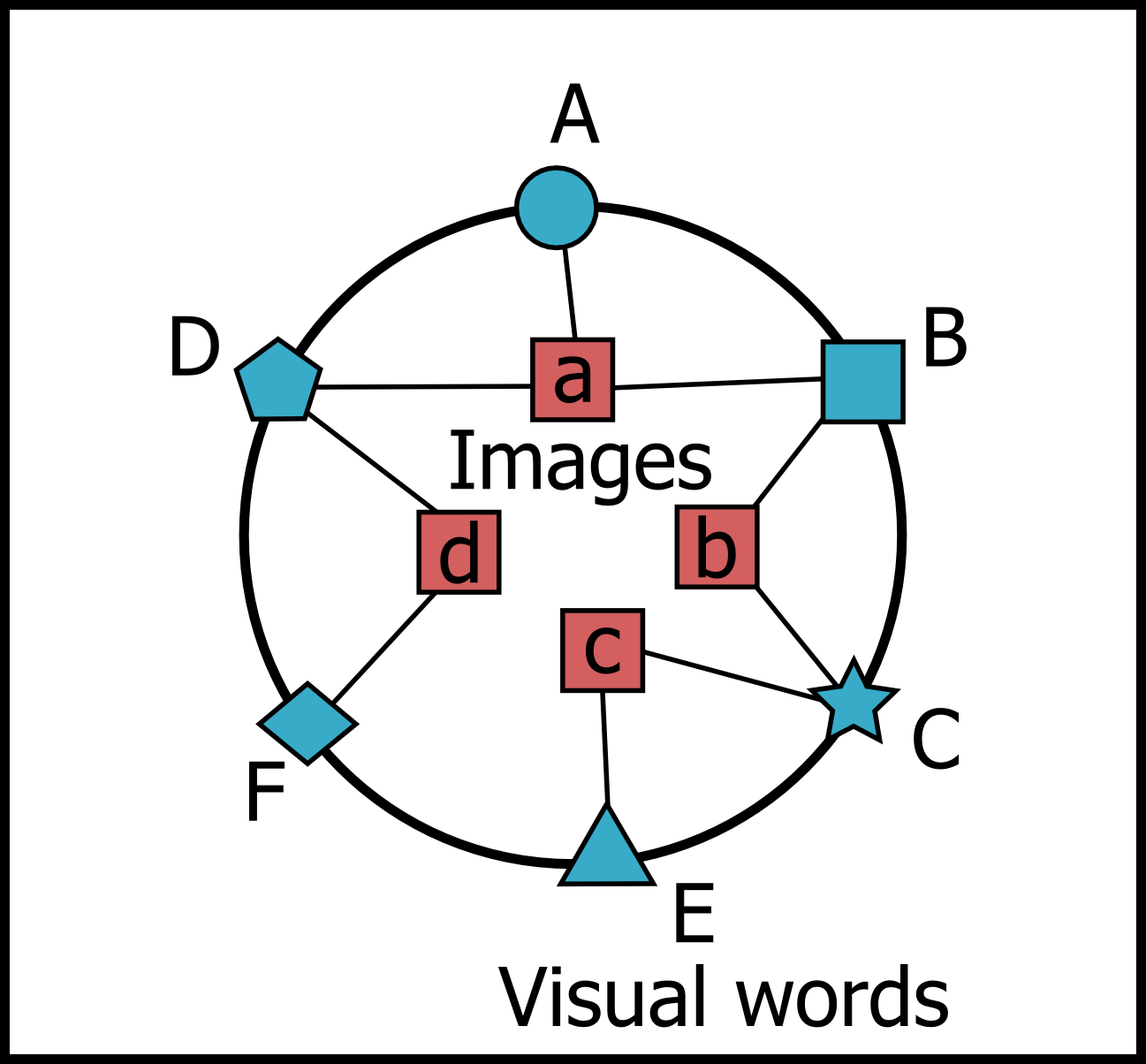
すべての画像をアンカーマップとして可視化する.
ここで,
アンカーマップの境界に位置するアンカーノードの順番は,
画像間配置における視覚的乱雑さを低減するように,
遺伝的アルゴリズムを用いて最適化される.
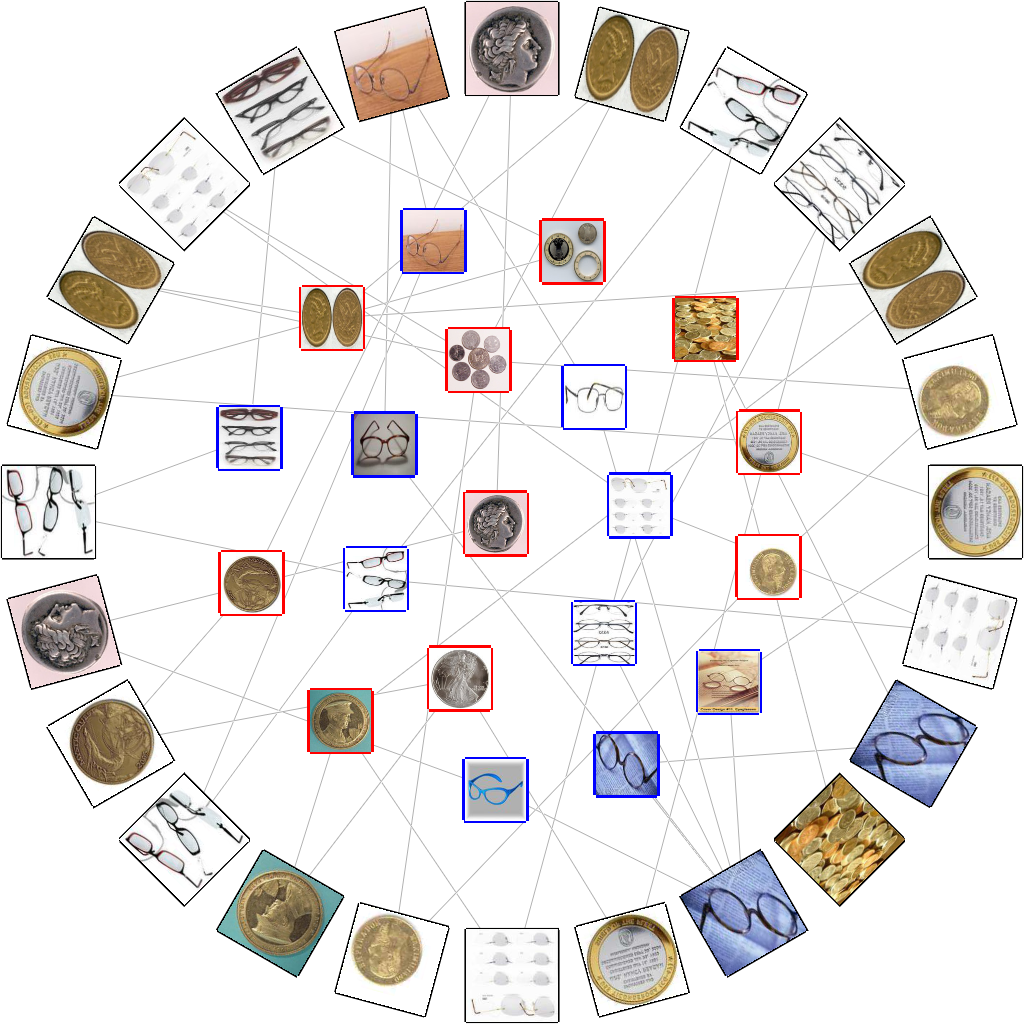
より大きな画像データベースを扱うために,
最も類似している画像ペアをひとつずつまとめることで,
画像の階層的なクラスタリングも実現している.
ここでは,
画像感の類似度は重み付き Jaccard 係数を用いて評価している.
我々の手法では,
アンカーマップの中央の領域にボロノイ分割も導入して,
サポートベクターマシンにより画像がどのようにカテゴリ化されるかを視覚的にとらえることも可能としている.
|
|
|
図2. BoF モデルの概要.
|
Last Modified: Aug 21, 2015