
GRADUATION THESIS RESEARCH
Theme 1: Spoken Language Processing Technology
Spoken language processing technology is one of the main components of the human-machine interface. Speech is the most natural way of human communication and the ability to talk with computers as we talk to each other is a long lasting dream as well as hot research topic. There are already quite significant achievements in this field, and the technology has penetrated some areas of our life.
The three main components of the spoken language technology include speech recognition, speech synthesis and natural language processing (NLP). Speech recognition transforms the human speech into text which can be processed by NLP and the result can be transformed again into human speech by speech synthesis. The number of possible applications of the spoken language technology is enormous: from controlling machines by voice commands to speaking freely and having your speech translated into another language.
Students will learn the basics of the spoken language technology and concentrate on some project. Several possible projects are listed here, but the final decision will be made by discussion with every student. Students who:
- Can program in C/C++ and want to learn new languages like Python or Perl,
- Can work hard and like to study new things,
- Want to improve their English speaking skills
are especially welcome.
Project 1.1: Speech Recognition

The goal of automatic speech recognition (ASR) is to transform human speech into text. It is a key technology for building natural human-machine interfaces. Using ASR we can talk to computers and they will respond respectively. There exist various speech recognition systems. Those used for command and control of machines can recognize few hundred words spoken by anybody and in the presence of high level noise. Others designed for dictation of letter, orders or similar documents, can recognize tens of thousands of words, but usually from a particular speaker and in relatively quite room.
The work under this project currently includes development of small scale recognition system, such as for digit recognition or voice dialing. Testing, evaluation and running live system is also part of the project. In addition, development of speech collection software will be required as a first step. Extensive use of software tools, such as Hidden Markov model tool kit (HTK) and Julius decoder will be essential for the project success.
Project 1.2: Speech Synthesis and Speech Reconstruction
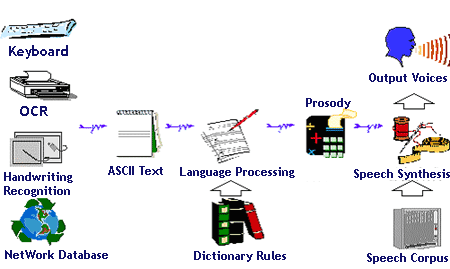
Text to Speech (TTS), or speech synthesis technology's main task is to convert text into intelligible voices, in other words, let machines talk like human beings. Speech synthesis is the other key technology in realizing human-machine speech communication, and establishing automatic dialog systems. It's a particularly interdisciplinary field, involving acoustics, linguistics, computer science and signal processing.
The work under this project involves implementation of some signal processing algorithms for speech analysis and reconstruction. In addition, experimental work with some existing software packages, such as Festival, HTK and others will be necessary. For speech synthesis, new technology based on Hidden Markov model will be pursued. As shown in the picture, there are several steps in the process of speech synthesis: 1) Text generation (keyboard input or OCR or database), 2) Text processing using language pronunciation rules, 3) Generation of prosodic information, and 4) Synthesis of speech signal using speech database.
Project 1.3: Speaker Recognition

In contrast to speech recognition where we don't care about the speaker identity, the goal of speaker recognition technology is to find out who is speaking. Often, we need to know, who from a group of known speakers is actually talking. This is called speaker identification. Another task of the speaker recognition technology is to verify whether the speaker is who he/she claims to be. This is called speaker verification. Speaker recognition technology is the main tool for finding "who spoke when" in a recording of meeting, seminar or news broadcast. This task is so important that it received special name: speaker diarization.
This project will require building speaker models from data. This means that from the speech from one speaker a model is trained using machine learning algorithms. There are some tools for model training, but in many cases, programming of new algorithms will be necessary.
Project 1.4: Pronunciation Evaluation
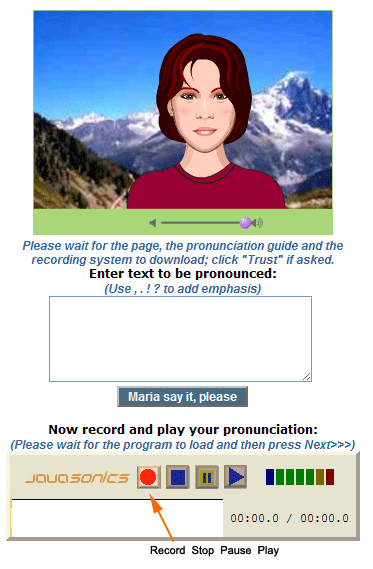
When studying foreign language, it is important to learn the correct pronunciation. This is especially true for Japanese learners of English. It is impossible to have human teacher all the time, but having machine to automatically evaluate your pronunciation and to show where you make mistakes is a viable alternative. Such machines use speech processing technology to judge the pronunciation proficiency and are designed to work in an interactive manner mimicking a real teacher as the picture shows. Users are asked to read some text and then the system analyses each word for pronunciation mistakes. Most advanced systems can even check for reading fluency as well.
In this project, work will be concentrated mainly in building the system interface and various modules for pronunciation evaluation. This includes speech input module, speech signal processing module, speech recognition module and others. To some extend, this work will be done in collaboration with the Phonetics Lab (Prof. Wilson) at The University of Aizu.
Project 1.5: Audio Segmentation

Audio segmentation is the task when we need to segment or find the start and end time of portions of audio signal which correspond to one event. For example, at the picture the is a recording of "voices" of three animals: bee, cow and rooster. The task then will be to find when each of these animals is "speaking" or to segment the signal into three segments corresponding to each animal. Although it seems easy, this task is quite challenging especially if we do not know how many or which animals are there.
Work under this project will include development and programming of algorithms for audio segmentation as well as building and training models for various "animal" and human voices. In some cases, audio signal may include music, advertisements and other events which complicate the task and need clever ways of dealing with them.
Theme 2: Music Information Processing
Current portable devices capable of playing music have gigabytes of memory and can play thousands of songs. Efficient songs management requires automatic methods to discriminate the music characteristics such as genre or mood.
Applications of music processing technology are numerous including automatic play list generation, music search and recommendation according to genre, mood or similarity to the current song, and many others.
Students will learn the basics of pattern recognition theory and some fundamental signal processing algorithms for music feature extraction.
Project 2.1: Music Genre Recognition

There are many music genre out there, but the most popular and familiar ones are about ten: blues, classical, country, disco, hip-hop, jazz, metal, pop, reggae and rock. Often, musical songs come in mp3 format which has tags (ID3 tags) giving some information about the song such as title, artist, album. etc. Sometimes, there is a genre tag, but it is mostly missing. How do we find the music genre then? One way is to use music signal processing technology to do that. In this project, using collection of musical songs, a music genre recognition system should be developed and evaluated. There are various signal processing and pattern recognition software tools which can be used for this purpose. In addition, the GT project may be focused on embedding an already built genre recognition system in web or mobile phone application such as music search according to the genre or play list generation, etc.
Project 2.2: Music Mood Recognition

Similarly to the music genre recognition, music mood recognition tries to identify the overall mood of the music piece using only the music signal. In contrast to genres, however, music moods are not so clearly defined and, thus, are more difficult recognize. There are two main approaches to defining music mood. One is just to put labels (or tags) on each song indicating its mood, such as "happy", "sad", "relaxed", "angry", etc. There are many types of mood and the difficulty is that different people may perceive the same song as having different mood. The other method is based on some psychological studies which define mood or emotion as a point in two dimensional space with coordinates of arousal and valence. This way, each song's mood has two values: one for arousal and one for valence. The goal of the project will be to develop a music mood recognition system and evaluate it.
Project 2.3: Music Similarity

Some times people want to listen to music which is, for example, similar to the one they are currently listening. It could be from the same genre or same mood, or even from the same artist, or not. It should be just similar. In such cases, it is important to define a similarity measure between two musical songs. In other words, we would like to be able to calculate a "distance" which would show how similar are two songs. If the distance is small, then the two songs would be very similar. If, in contrast, the distance is big, then songs should be quite different. In this project, various definitions of "distance" will be investigated and an mobile phone or player application will be developed.