|
This web page is prepared for providing research materials of our project on gaze-based interaction for context-aware placement of items.
|
Context-aware placement of items |
|
Proper placement of items significantly influences how well viewers can find their favorites, especially when they try to select products in the digital signage displays.
This leads to the new demand for sophisticated placement of items based on their categories according to the context in which viewers explore their preferred choices.
In this project, we developed an approach for optimizing the placement of items by respecting the underlying context in the search for favorites. Our approach starts with formulating the static placement of items as a constrained optimization problem, in which we incorporated useful design rules that highlight the underlying categorization of the items. We then extend this idea to accommodate the dynamic placement according to the context in which users explore their preferred choices. This is accomplished by adaptively adjusting the priority of each item based on the distribution of visual attention obtained by an eye-tracking device. In particular, we constructed the context map for understanding the relevance between the items by taking advantage of topic-based text mining techniques. |
Results |
|
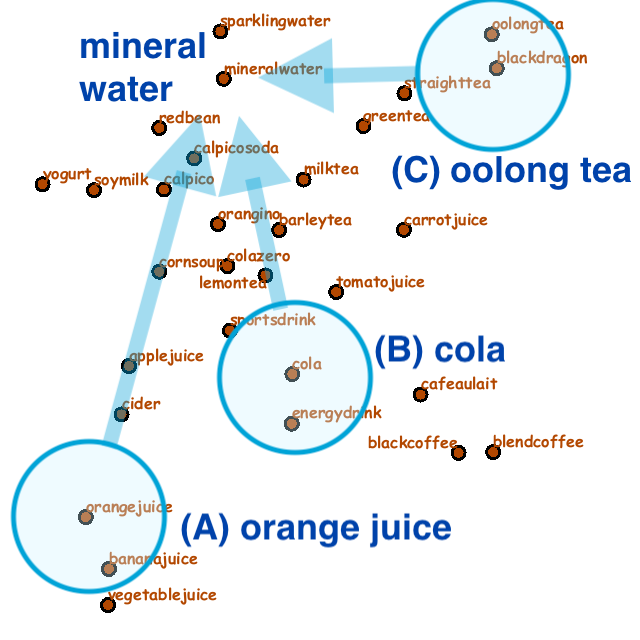
Figs. 1 and 2 exhibit the first example,
in which we implemented a virtual vending machine of drinks.
Here, we prepared three scenario for exploring drinks in the grid layout:
(A) from orange juice to mineral water,
(B) from cola to mineral water, and
(C) from oolong tea to mineral water.
We compared how the placement of drinks changed according to the search context through the comparison between the results obtained by following the three scenarios.
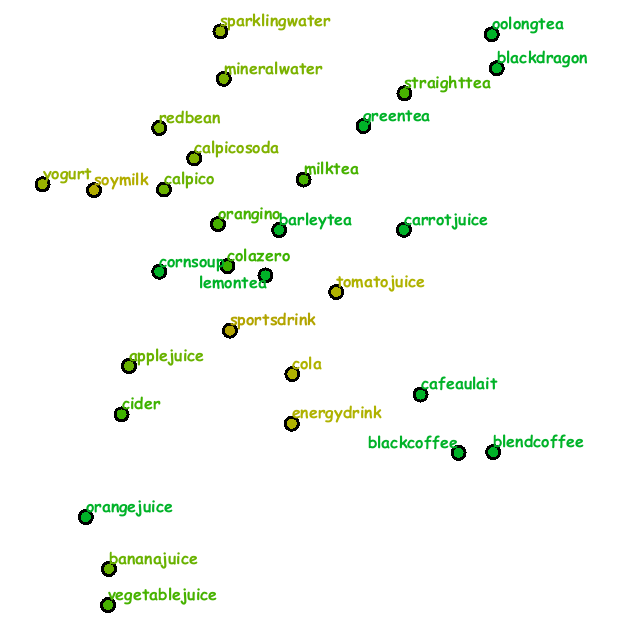
Fig. 1(a) and (b) present the initial grid placement of drinks and the corresponding context map computed by applying topic-based text mining methods to explanatory texts of the drinks.
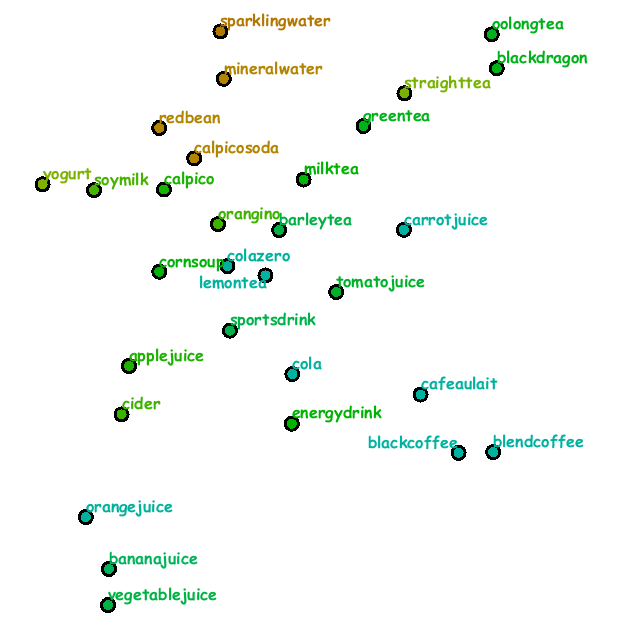
We also clarify how our focus will shift over the map according to the three scenario in Fig. 1(b).
|

|
|
|
Fig. 1: Three scenarios for exploring drinks with a virtual vending machine. (a) The initial grid placement of drinks. (b) The context map with three scenarios for exploring drinks.
|
|
|
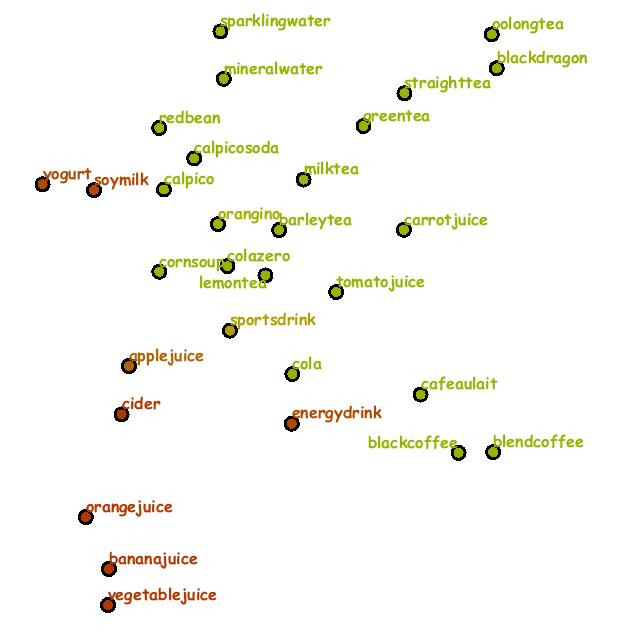
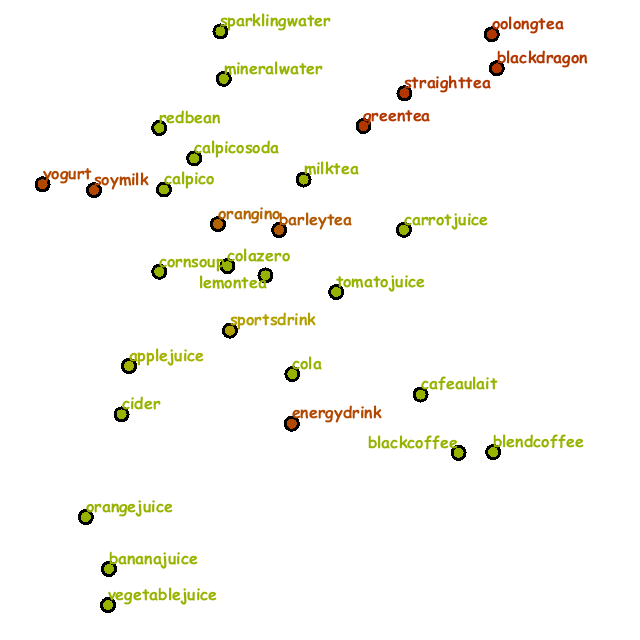
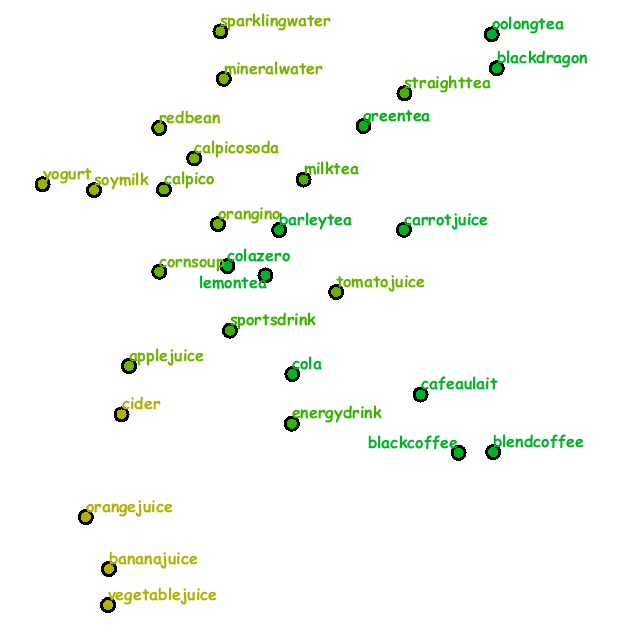
Fig. 2 demonstrates how the placement of drinks changed step by step according to the three scenario.
Note that the color of each plot and drink name label changes from blue to green to red in the context maps as the corresponding priority values increase.
In Scenario (A),
orange juice on the right of the middle row first draw attention and thus an apple juice bottle and a yogurt brick carton newly appeared since they were in the local neighborhood of the orange juice in the map.
Once the focus shifted to the mineral water,
the layout still contained multiple orange and apple juice bottles first while they were replaced with mineral and sparkling water bottles in the end.
In Scenario (B),
more cola bottles with its friend zero cola joined in the placement while the number of cola bottles and the like decreased as the number of mineral and sparking water bottles increased.
Nonetheless, the layout still kept more soda bottles in the end in the sense that the choice reflected the search context of the viewer.
The same can be applied to Scenario (C) in which oolong tea bottles together with its mates green tea and black tea bottles were newly lined up.
They were replaced with mineral and sparking water bottles at last while the grid still contained more tea bottles when compared with the results in other scenarios.
These results allow us to confirm that the respective contexts in the search for drinks were maximally reflected in the choice of drinks thanks to the use of the context maps.
|

|
|

|

|

|
|

|
|

|
|

|

|

|

|

|

|

|
|
| (A) | (B) | (C) | |||
|
Fig. 2: Changes in the placement of drinks according to the three scenario (from top to bottom in each column). (A) From orange juice to mineral water. (B) From cola to mineral water. (C) From oolong tea to mineral water.
|
|||||
|
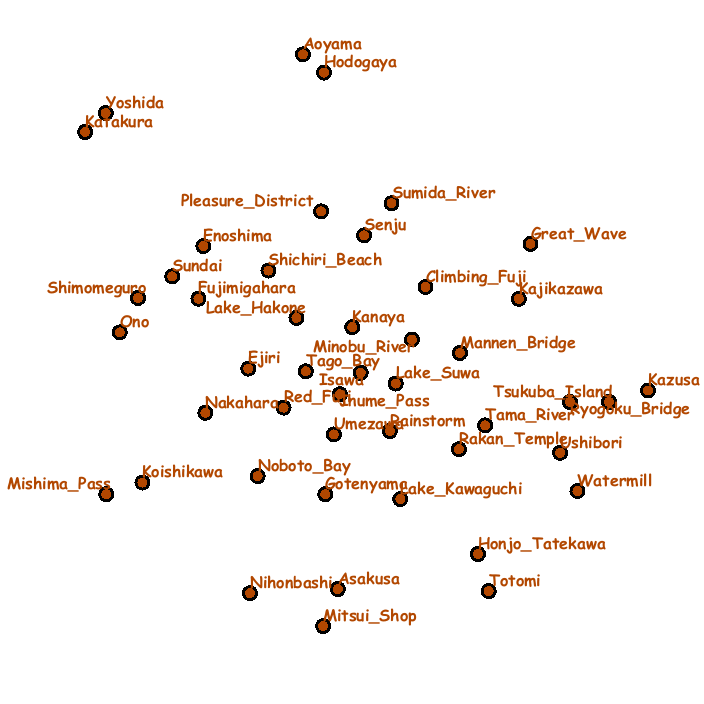
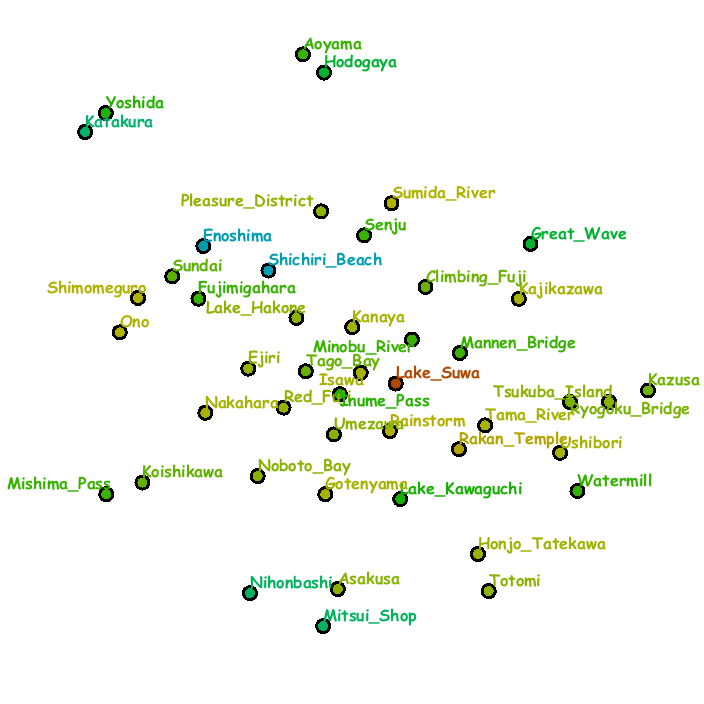
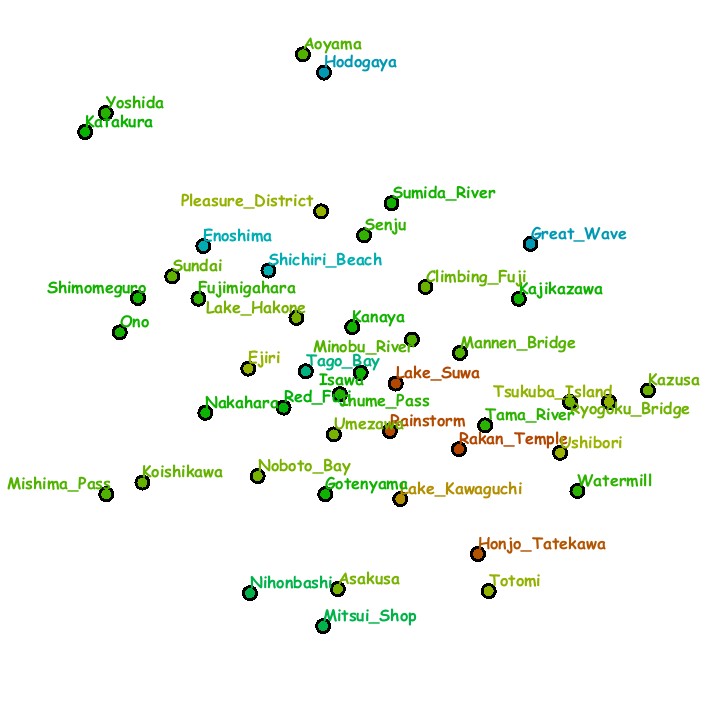
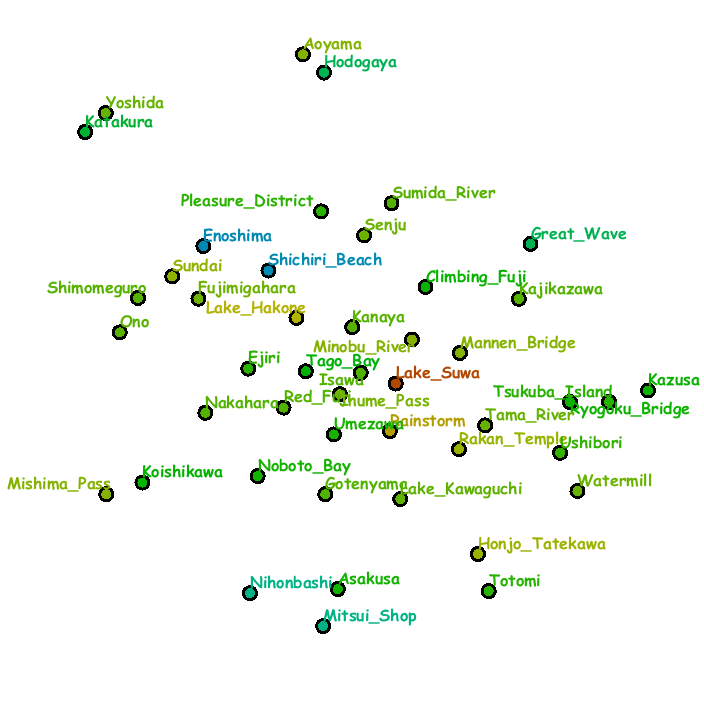
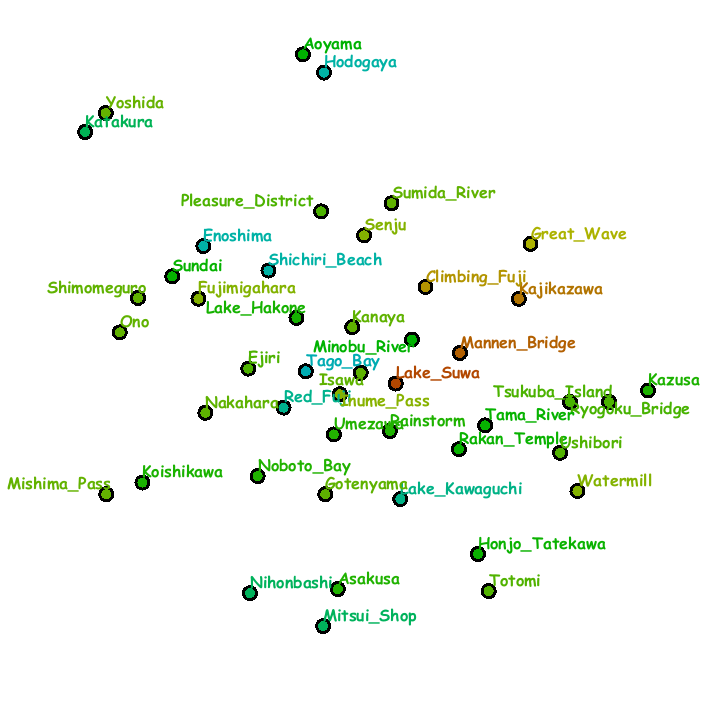
Fig. 3 demonstrates a digital information wall implemented on our system into which we incorporated the series of landscape woodblock prints called Thirty-Six Views of Mt. Fuji, which were created by the famous Japanese Ukiyo-e artist Hokusai.
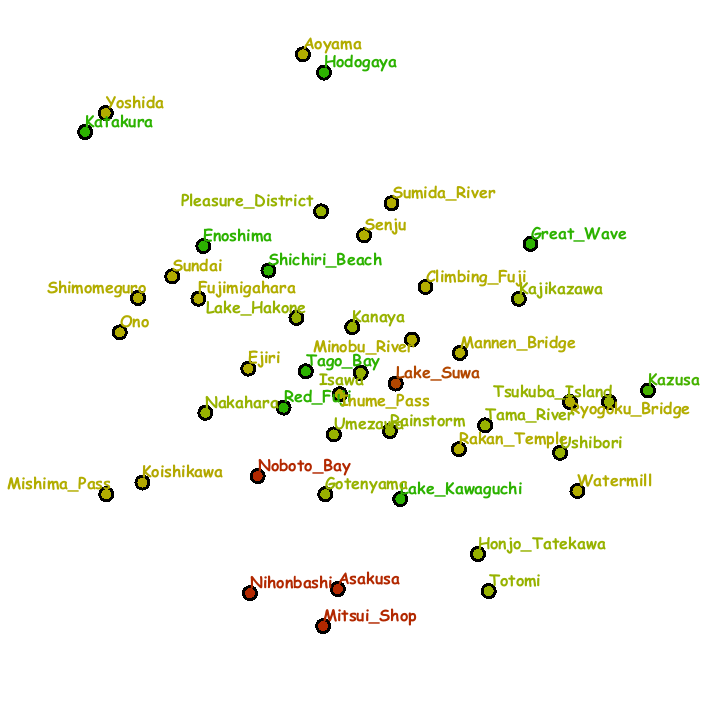
The sequence of snapshots were obtained by freely exploring favorite items and the placement of images were updated once focused areas of attention were extracted through the eye-tracker.
The context map was created again by analyzing the annotation texts for the respective artistic printings.
In this setup,
multiple slots are grouped to form a block matrix so that we can replace multiple small images with a single large one.
|

|
|

|
|

|
|

|
|

|
|

|
|
|
Fig. 3: System snapshots of exploring landscape prints in the series of Thirty-Six Views of Mt. Fuji (from left to right and top to bottom). Each slot consists of the grid placement of images (left) and the context map (right).
|
|||
Paper & VideoShigeo Takahashi, Akane Uchita, Kazuho Watanabe, and Masatoshi Arikawa, Context-Aware Placement of Items with Gaze-Based Interaction accepted for presentation in the 13th International Symposium on Visual Information Communication and Interaction (VINCI 2020), 2020. |