Introduction
Developing effective visual categorization techniques is crucial to accelerate image retrieval from databases due to the rapidly increased data size. The bag-of-features (BoF) model is one of the most popular and promising approaches for extracting the underlying semantics from image databases. Nonetheless, the associated image categorization approaches based on machine learning techniques may not convince us of its validity since we cannot visually verify how the images have been classified in the high-dimensional image feature space.
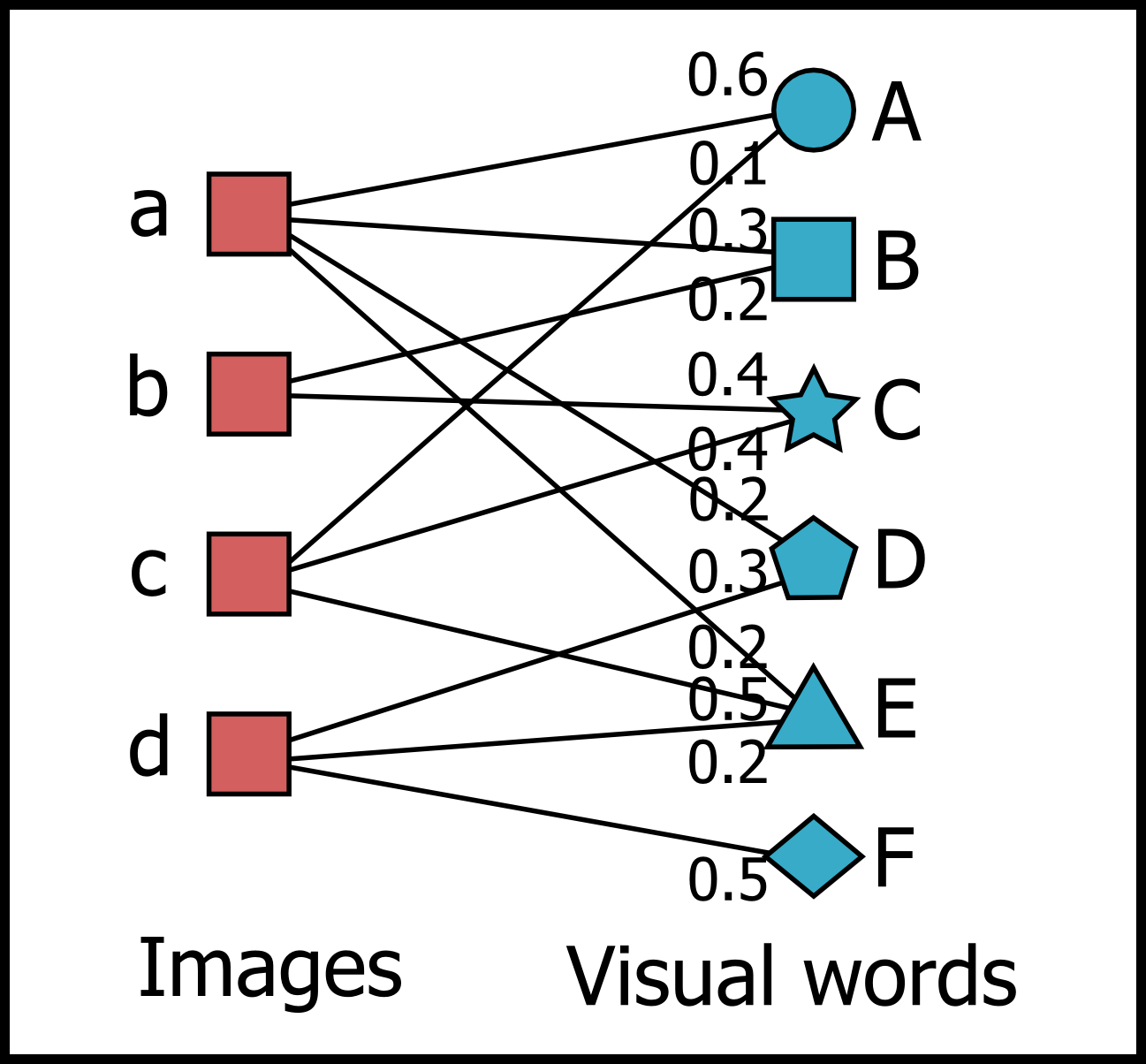
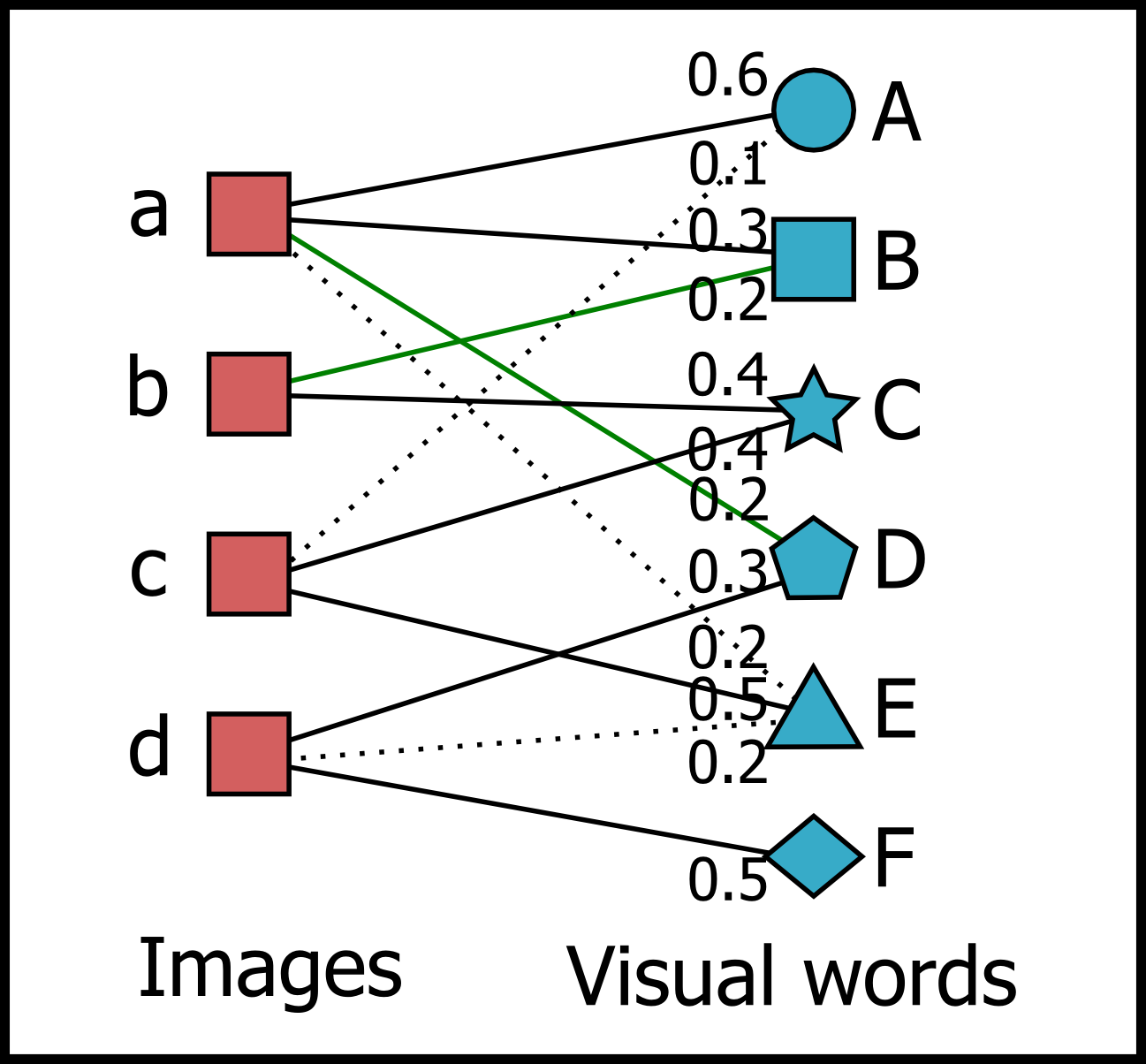
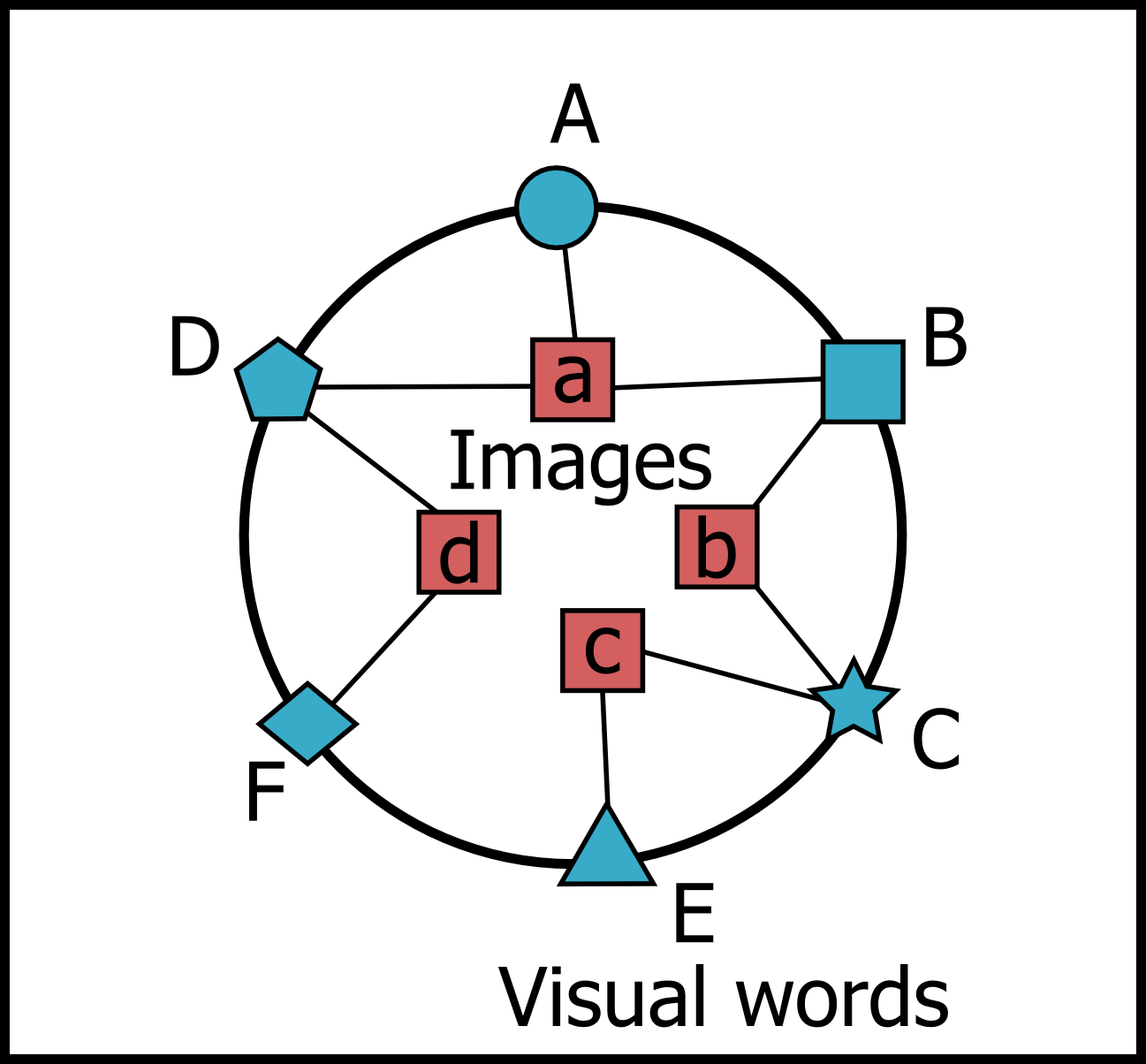
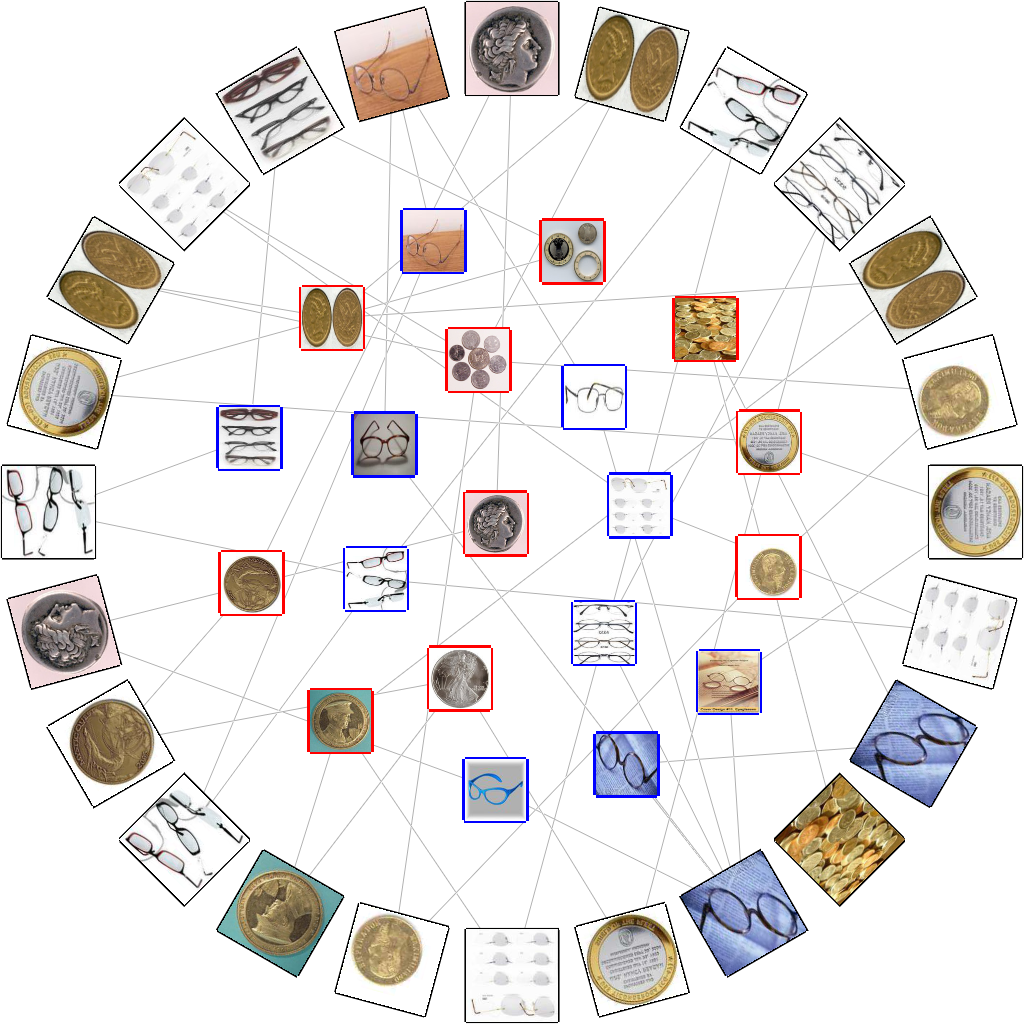
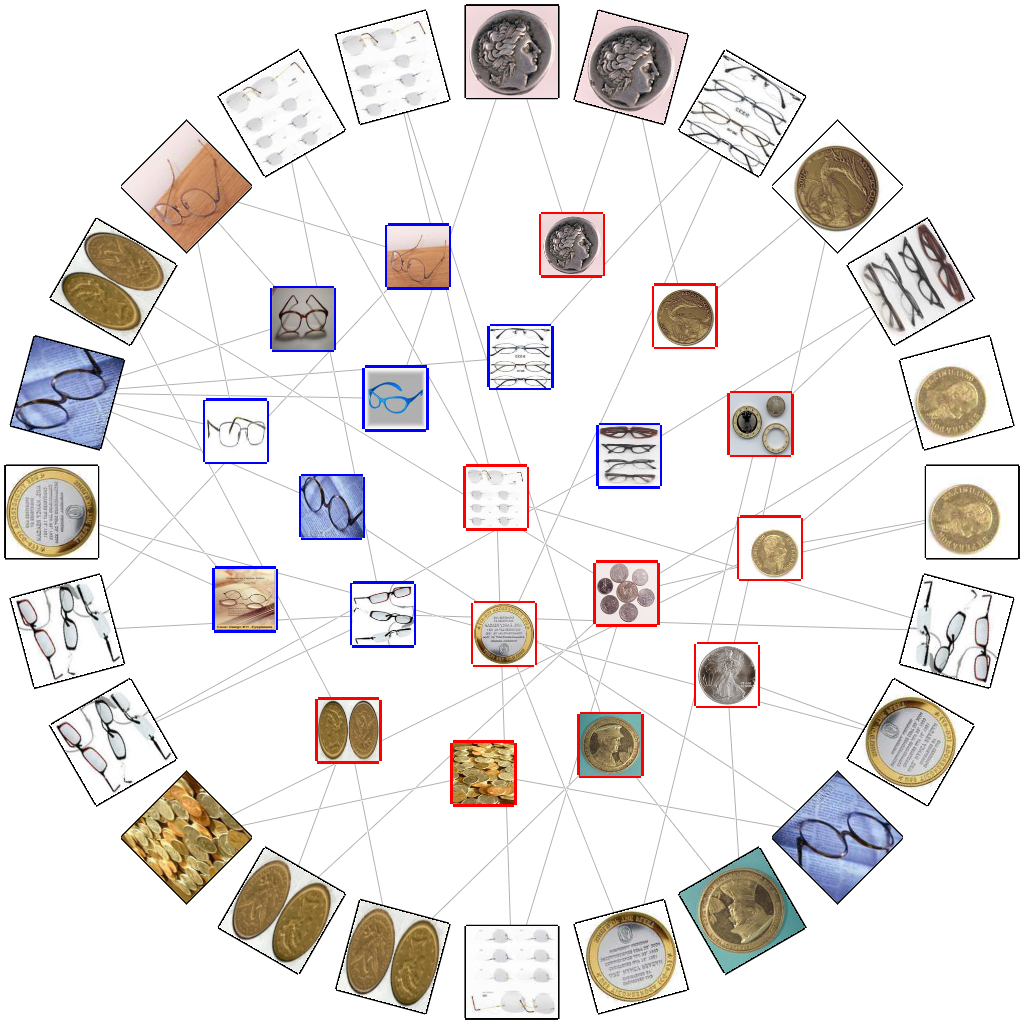
Our work aims to visually rearrange the images in the projected feature space by taking advantage of a set of representative features called visual words obtained using the bag-of-features model. The main idea is to associate each image with a specific number of visual words to compose a bipartite graph, and then lay out the overall images using anchored map representation, as shown in Figure 1.
|