Energy-Efficient Architectures: From Bio-Inspired AI SoCs to Green Computing
Principal Investigators: Abderazek Ben Abdallah (PI), Zhishang Wang (PI)
Our research in power/energy-efficient computing systems is critical for addressing the growing demand for more powerful and sustainable technology. As our reliance on computing devices increases, so does the need to manage their energy consumption. Efficient computing systems can reduce energy costs, minimize environmental impact, and extend the battery life of portable devices. Our research drives innovation in hardware and software design, leading to smarter, greener technologies that benefit both users and the planet.
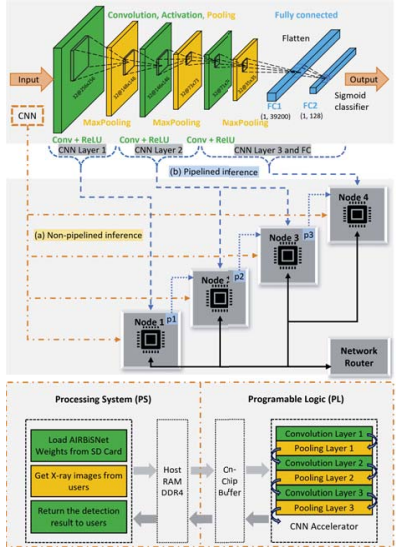
AIRBiS: Reconfigurable AI-Inference Acceleration
This project introduces AIRBiS (AI-powered Reconfigurable Biomedical System), a hardware platform specifically engineered for scaling deep-learning inference in resource-constrained environments. By employing specialized hardware accelerators, the platform can perform complex medical diagnostics with an accuracy of 95.2%. The architecture is designed to be self-contained and reconfigurable, adaptive to various neural network topologies while maintaining an energy-efficiency profile 13 times better than conventional general-purpose processors.

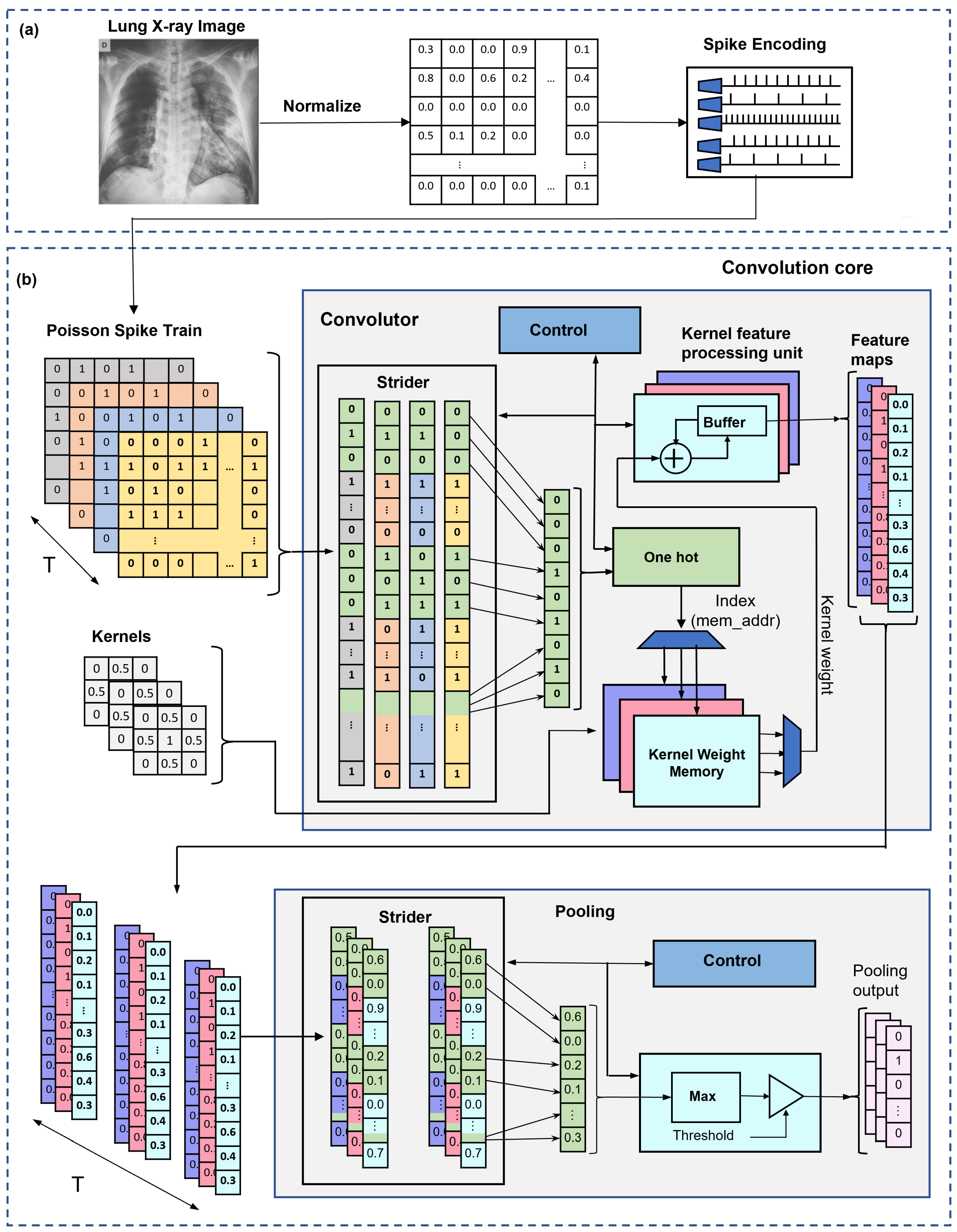
3D-NoC Based Neuromorphic Computing
Traditional Artificial Neural Networks (ANNs) are often computationally expensive and ill-suited for real-time edge devices. Our research focuses on Spiking Neural Networks (SNNs) integrated into 3D Network-on-Chip (3D-NoC) architectures. By mimicking the brain's spatio-temporal information processing, these neuromorphic systems offer high reliability and fault tolerance. Our proposed 3D-NoC routing scheme ensures robust communication even under hardware failure, consuming 32% less power than standard ANN-based systems.
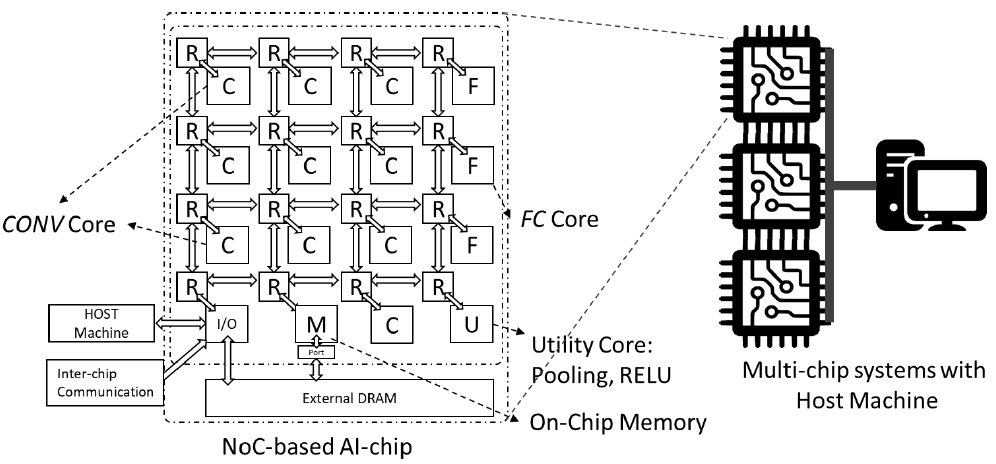
Patent: High-Performance AI Processor
This patented technology focuses on a novel AI Processor architecture designed for high-throughput and energy-efficient execution of modern machine learning workloads. The design emphasizes a modular hardware approach that optimizes data flow between processing elements, significantly reducing the energy overhead associated with memory access. This architecture serves as the foundation for the next generation of embedded AI systems, providing necessary computational power for autonomous edge devices.
[Patent No. 7699791] (June 20, 2025) ? Abderazek Ben Abdallah, Hoang Huang Kun, Dang Nam Khanh, Song Janning, "AI Processor" [Source]
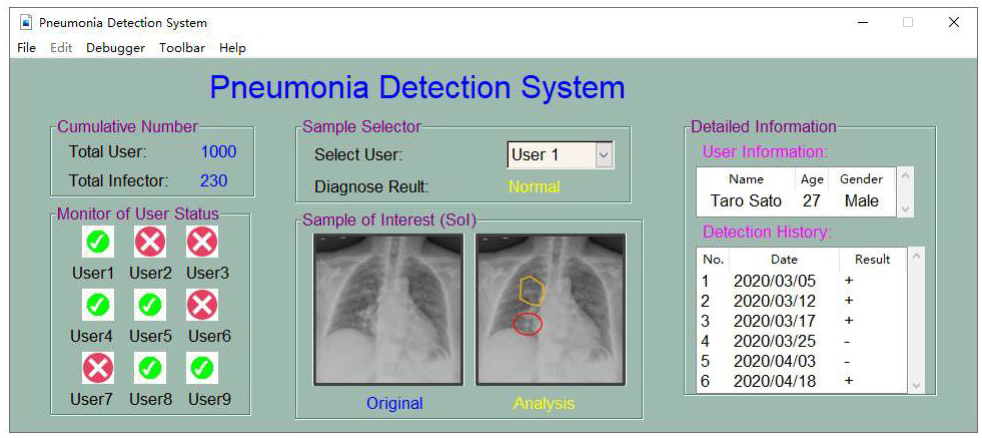
Embedded Multicore SoC for Real-time Health Monitoring
As healthcare shifts toward personalized and remote monitoring, there is a critical need for SoCs that can handle real-time signal processing on-body. This project explores the design of embedded multicore systems specifically for ECG (Electrocardiogram) processing. Unlike traditional systems that merely collect and transmit data, our SoC performs local, real-time feature extraction and anomaly detection, ensuring long-term use on portable and wearable devices.

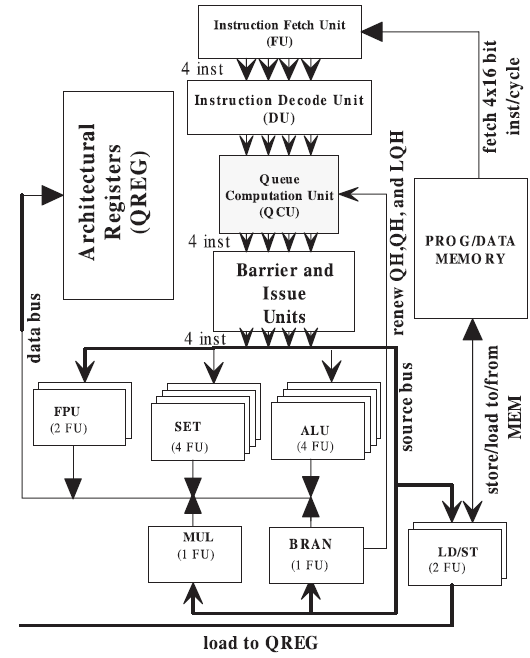
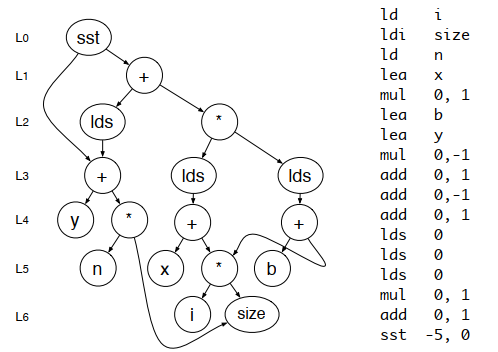
Low-Power Queue Processor Architecture
The Queue computation model provides an alternative to traditional register-based architectures by utilizing a circular queue-register to manage operands. This project researches a novel parallel processor that eliminates "false dependencies," which are a primary source of complexity and power consumption in modern CPUs. By removing the need for power-hungry hardware like register renaming, the Queue Processor achieves high instruction-level parallelism (ILP) with minimal hardware overhead. Our research includes the development of a complete cross-layer tool-chain?including ILP-aware compilers and cycle-accurate simulators?to optimize the execution of embedded applications.

Green Computing
Our research is dedicated to the design and utilization of computers with minimal environmental impact, encompassing efforts to reduce energy consumption, minimize waste, and employ sustainable materials. By integrating cutting-edge technologies and innovative methodologies, we aim to develop solutions that not only enhance the efficiency and functionality of computing systems but also contribute to the preservation of our planet. Our multidisciplinary approach involves collaboration with companies and experts in various fields, ensuring that our findings and implementations are both practical and impactful.
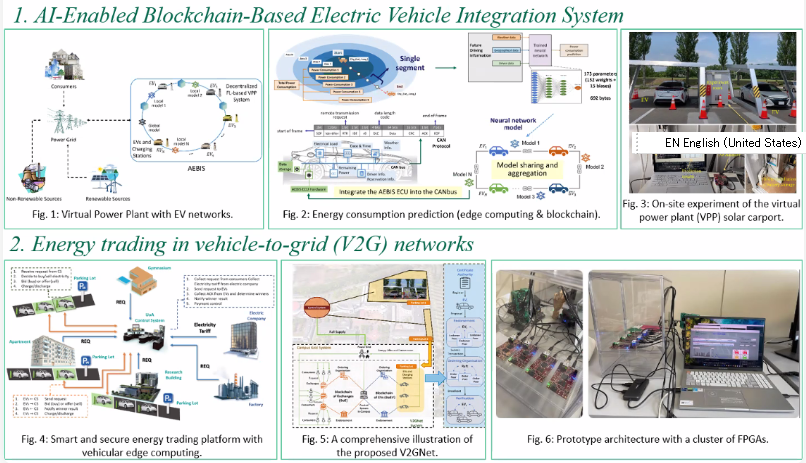
In addition, our research in AI-powered EV Energy Harvesting and Management represents an advanced approach to optimizing energy efficiency and sustainability. The integration of AI enables intelligent decision-making and real-time adjustments, ensuring that energy is harvested and managed most efficiently.
Furthermore, our Trustworthy Campus Energy Trading System is a cutting-edge initiative designed to enhance energy efficiency by enabling the secure and efficient trading of energy resources within the campus community. This system leverages advanced technologies such as blockchain, AI, and IoT to facilitate transparent, reliable, and real-time energy transactions among various campus buildings, facilities, and renewable energy sources.
Related Projects:
- AI-powered EV Energy Harvesting and Management
- Trustworthy Campus Energy Trading System
- AI-enabled Vending Machine with Off-grid Energy Harvesting
- Edge Automotive-grade Chips and Systems
Registered and Provisional Patents:
- [Patent No. 7239099] (March 14, 2023) - Abderazek Ben Abdallah, Khanh N. Dang, Masayuki Hisada, "TSV fault-tolerant router for 3D-NoC" [Source]
- [Patent No. 6804072] (December 4, 2020) - Abderazek Ben Abdallah, Masayuki Hisada, "Virtual Power Platform Control System" [Source]
- Electricity Trading System and Method (Provisional 2022-022472) - Abderazek Ben Abdallah, Wang Zhishang, Masayuki Hisada
- EV Power Consumption Prediction for Smart Grid (Provisional 2023-020162) - Abderazek Ben Abdallah, Wang Zhishang, Khanh N. Dang, Masayuki Hisada